※ もともと社内公開していた記事を加筆修正したもので、最近Pythonを始めた人、特にデータ分析や機械学習をするために始めた人を主な対象にしています。
TL;DR
- 1MB、10000個のファイルをコピーする処理をリストとジェネレータで比較した
- ローカルのmacOSで比較
- リストの場合: 最大メモリ使用量9737.562 MiBだった
- ジェネレータの場合: 最大メモリ使用量17.668MiBだった
- 上記を元にスペックを決めたGCEインスタンスで比較
- インスタンススペックは最大値に引きずられる
- ジェネレータなら1時間あたり約$0.007のインスタンスで実行できる
- リストなら1時間あたり約$0.104のインスタンスが必要になる
- 月額換算すると約8000円の差になる
- 執筆時のレート111.42円で計算
はじめに
AWSやGCPなどのクラウドを使うとマシンのスペックを気軽にあげることができ便利です。 しかし、スペックをあげるとその分コストもあがります。 そのようなインフラコストを意識し始めた時、まず手がつけやすく効果も実感しやすいのが「リストの代わりにジェネレータを使う」ことです。
「ジェネレータを使いましょう」は今や入門書にも書かれていることですが、実際のところ「リストで書いたコードが上手く動いてる」のでついついそのままリストを使いがちになっている人も多いと思います。 そこで、この記事ではリストとジェネレータの「メモリ効率」にフォーカスし、具体的なメリットを示すことで「ジェネレータを使ってみよう!」と思ってもらえればなと思います。
ジェネレータとは?という話は触れません。 ジェネレータの使い方を知りたい方は、Effective Pythonの項目16、Fluent Pythonの14章などの書籍やWeb上にある記事を確認してください(Effective Pythonのほうがサクッと読めます。)。
比較の詳細
今回使ったコードはこちらにあります。
10000個のダミーファイルの中身をメモリ上に展開するため、10GB以上のメモリを必要とします。
実行時に--genフラグをつけるとリストの代わりにジェネレータを使うため、省メモリで実行できます。
メモリのプロファイリングはpsutilパッケージとmemory-profilerパッケージを利用しました。
プロファイリングしたい関数に@profile(インポート不要)をつけ、python3 -m memory_profiler copy_file.pyで実行すると次のように行単位でメモリ使用量が表示されます。
ただし、メモリの比較はオーバヘッドがかなりあるため、処理が遅くなります。
ローカルでリストを使った場合
リストを使った場合は最大で9737.562 MiBのメモリを使用していました。
[rhoboro]~/work % time docker run -it --rm copy:latest
...
Filename: copy_file.py
Line # Mem usage Increment Line Contents
================================================
12 14.855 MiB 14.855 MiB @profile
13 def call_list():
14 9737.562 MiB 9644.703 MiB for i, dummy in enumerate(do_list('dummy', 10000)):
15 9737.562 MiB 0.715 MiB with open('dest' + str(i), 'w') as f:
16 9737.562 MiB 1.152 MiB f.write(dummy)
docker run -it --rm copy:latest 0.06s user 0.20s system 0% cpu 6:02.43 total
ローカルでジェネレータを使った場合
比較に使ったコードは、実行時に--genフラグをつけるとジェネレータで動きます。
ジェネレータを使った場合は最大でも17.668 MiBのメモリ使用量で済んでいます。
[rhoboro]~/work % time docker run -it --rm copy:latest --gen
...
Filename: copy_file.py
Line # Mem usage Increment Line Contents
================================================
27 14.855 MiB 14.855 MiB @profile
28 def call_gen():
29 17.668 MiB 1.047 MiB for i, dummy in enumerate(do_gen('dummy', 10000)):
30 17.668 MiB 0.000 MiB with open('dest' + str(i), 'w') as f:
31 17.668 MiB 0.770 MiB f.write(dummy)
docker run -it --rm copy:latest --gen 0.04s user 0.17s system 0% cpu 2:47.83 total
メモリ使用量に制限をつけてみる
Dockerを利用しているため、-mオプションで簡単に利用できるメモリ量に制限をかけることができます。
ここではGoogle Cloud PlatformのGCEインスタンスで選べる最低スペックである0.6GB = 600MBに制限して実行してみました。
ローカルでリストを使った場合
リストの場合実行には10GB程度必要なので、当然のことながら完了できません。 したがって、実行途中で落ちてしまいます。 クラウド上のVMを利用している場合は実行してるつもりが途中で落ちていて課金だけ発生していることになりかねません。
[rhoboro]~/work % time docker run --rm -it -m "600M" copy:latest
docker run --rm -it -m "600M" copy:latest 0.04s user 0.02s system 0% cpu 9.071 total
# リターンコードも0でないのでエラーだとわかる
[rhoboro]~/work % echo $?
137
ローカルでジェネレータを使った場合
ジェネレータの場合は600MBもあれば十分なので問題なく実行できました。
[rhoboro]~/work % time docker run --rm -it -m "600M" copy:latest --gen
...
Filename: copy_file.py
Line # Mem usage Increment Line Contents
================================================
27 14.832 MiB 14.832 MiB @profile
28 def call_gen():
29 17.645 MiB 1.047 MiB for i, dummy in enumerate(do_gen('dummy', 10000)):
30 17.645 MiB 0.000 MiB with open('dest' + str(i), 'w') as f:
31 17.645 MiB 0.770 MiB f.write(dummy)
docker run --rm -it -m "600M" copy:latest --gen 0.04s user 0.03s system 0% cpu 1:23.16 total
GCEインスタンスを使う
どちらもディスク容量を30GBに設定し、OSはコンテナ利用に最適化されているontainer-Optimized OS 69-10895.172.0 stableを使用しました。
リストでの処理がぎりぎり動くスペックの場合
vCPU x 2、メモリ13GBで1時間あたりの料金は約$0.104のインスタンスを選択しました(メモリ10GBだと落ちました。)。 割引込みで月額8456円です。
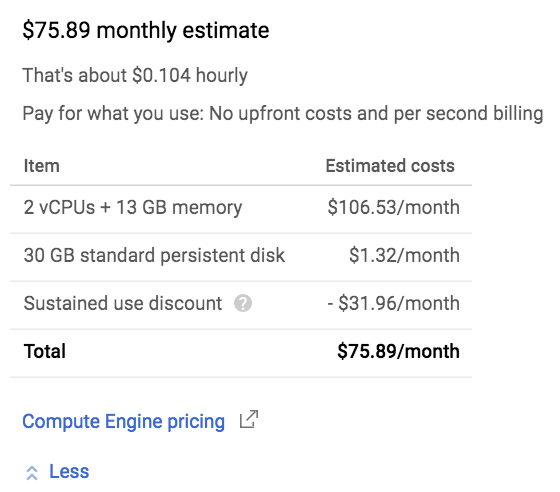
リストを使って実行すると次のようになりました。
rhoboro@list ~ $ time docker run --rm -it copy:latest
...
Filename: copy_file.py
Line # Mem usage Increment Line Contents
================================================
13 14.711 MiB 14.711 MiB @profile
14 def call_list():
15 10016.762 MiB 10002.051 MiB for i, dummy in enumerate(do_list('dummy', 10000)):
16 10016.762 MiB 0.000 MiB with open('dest' + str(i), 'w') as f:
17 10016.762 MiB 0.000 MiB f.write(dummy)
real 3m54.197s
user 0m0.014s
sys 0m0.016s
ジェネレータを使った場合もローカルとほぼ同様の結果になりました。
rhoboro@list ~ $ time docker run --rm -it copy:latest --gen
...
Filename: copy_file.py
Line # Mem usage Increment Line Contents
================================================
28 14.645 MiB 14.645 MiB @profile
29 def call_gen():
30 17.398 MiB 1.098 MiB for i, dummy in enumerate(do_gen('dummy', 10000)):
31 17.398 MiB 0.000 MiB with open('dest' + str(i), 'w') as f:
32 17.398 MiB 0.770 MiB f.write(dummy)
real 4m34.585s
user 0m0.015s
sys 0m0.008s
rhoboro@list ~ $
f1-microインスタンスの場合
f1-microは利用できる最低スペックのインスタンスになります。 vCPU x 1、メモリ0.6GBで1時間あたりの料金は約$0.07です。 割引込みで月額566円です。
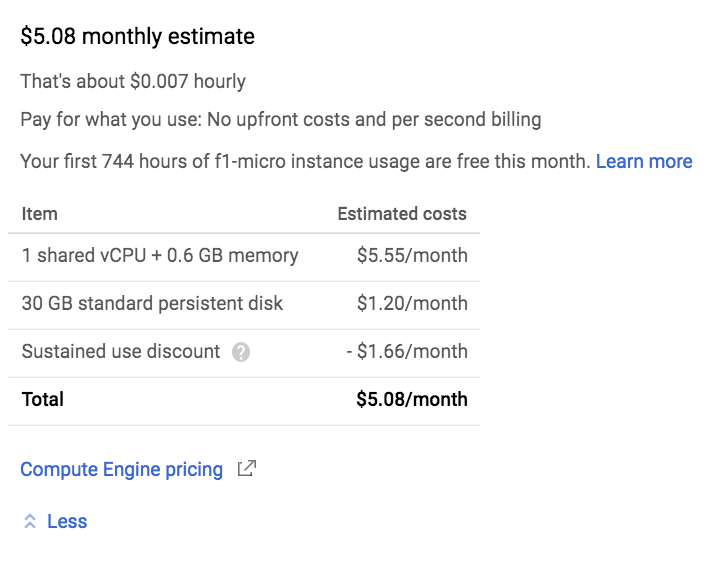
このインスタンスでは、スペック不足でリストでの実行は完了できませんでした。
rhoboro@generator ~ $ time docker run --rm -it copy:latest
real 1m37.716s
user 0m0.007s
sys 0m0.023s
rhoboro@generator ~ $ echo $?
137
ジェネレータを使ったコードはf1-microでも問題なく実行できました。
rhoboro@generator ~ $ time docker run --rm -it copy:latest --gen
...
Filename: copy_file.py
Line # Mem usage Increment Line Contents
================================================
27 14.824 MiB 14.824 MiB @profile
28 def call_gen():
29 17.695 MiB 1.105 MiB for i, dummy in enumerate(do_gen('dummy', 10000)):
30 17.695 MiB 0.000 MiB with open('dest' + str(i), 'w') as f:
31 17.695 MiB 0.770 MiB f.write(dummy)
real 5m21.917s
user 0m0.010s
sys 0m0.017s
簡単なコードの比較と処理の違い
今回は1つのPythonスクリプトにリストを使って処理するcall_list()とジェネレータを使って処理するcall_gen()を定義しています。
リストもジェネレータもイテラブルなので、for文で使う場合には使い方に差はありません。
# call_genも全く同じ
def call_list():
for i, dummy in enumerate(do_list('dummy', 5)):
with open('dest' + str(i), 'w') as f:
f.write(dummy)
リストを返すdo_list()は次のようになっています。
# 関数
def do_list(src, n):
files = []
for i in range(n):
with open(src + str(i)) as f:
files.append(f.read())
return files
リストの場合は最初に結果を格納するリストを用意し、そこにすべての要素を1つずつappend()していきます。
最後の結果までappend()し終わったらそのリストが関数の戻り値となります。
つまり、リストは全ての要素をメモリ上に保持されています。
対して、ジェネレータの場合は次のようにappend()せずに結果を即座に返します(yieldの行)。
for文は返された値を処理した後に次の要素を求め、この処理はジェネレータ関数の終端にたどり着くまで続きます。
結果的に1つずつ処理されるため、必要となるメモリは要素数には依存しなくなります。
# ジェネレータ関数
def do_gen(src, n):
for i in range(n):
with open(src + str(i)) as f:
yield f.read() # yield された値をfor文で利用できる
ファイル数が多ければ多いほどメモリ使用量の差は大きくなります。 そして、これはデータ分析や機械学習のような大規模データを扱う場合には非常に顕著な差としてあらわれます。 全件データや特徴量をリストで持つようなコードを書いていませんか?
まとめ
可能な限りリストを使うのはやめて、ジェネレータを使いましょう。 特に要素数が莫大な量になる処理をメインに扱うプロダクト、コードではとても恩恵を得やすいです。
利用は次のような点で若干の慣れが必要です、使わないと慣れないので使いましょう。
- ジェネレータは「消費」されるので一度
for文などで使うと空になります。何度も回したい場合はlist()で変換してあげる必要があります。 len()のように最後の要素までわかっていないといけない場合はlist()で変換してあげる必要があります。- 統計データなどは全データが揃っていないと求められないシーンも多いです。ただし、その場合でもリスト化はあくまでも呼び出し側が行えば良いので、機能を提供する側はジェネレータで返すのが良いです。
- ジェネレータを使う場合は「逐次処理でロジックを組めないか」「リストは最終手段」と強く意識することが大切です。逐次処理でできることは意外と多く、例えば合計値、平均値などは逐次処理でも算出できます。また、「逐次処理」ができるように書いておくと、将来的な並行処理の導入やストリームデータへの対応もしやすくなります。